

Introduzione: Quando l’IA incontra il mondo reale
Chiunque può trascrivere un audio chiaro e registrato in studio. Ma i contenuti reali—vlog, interviste sul campo, registrazioni in strada—sono tutt’altra storia.
Quando un parlante cambia improvvisamente lingua, quando il traffico copre la voce o quando un intervistato ha un forte accento, le trascrizioni AI tradizionali falliscono. Questo costringe i creator a ore di correzioni manuali noiose.
Oggi SubEasy è orgogliosa di presentare il nostro nuovo modello di trascrizione. Non ci siamo limitati a migliorare la precisione generale: abbiamo progettato questo modello per affrontare specificamente i 4 scenari più frustranti per i creator.
Ecco come si comporta il nuovo modello alla prova dei fatti.
1. Audio multilingue misto (Code-Switching)
Il problema: In riunioni internazionali o vlog di viaggio moderni, i parlanti spesso cambiano lingua a metà frase (code-switching). La maggior parte dei modelli esistenti forza la trascrizione in una sola lingua principale, trasformando la seconda lingua in un testo incomprensibile.
La soluzione del nuovo modello: Il nostro nuovo modello rileva istantaneamente i cambi di lingua. Come mostrato nel confronto qui sotto, dove il parlante passa dall’inglese allo spagnolo, il nuovo modello trascrive perfettamente entrambe le lingue.
 Un confronto che mostra il modello esistente in difficoltà con lo spagnolo, mentre il nuovo modello trascrive correttamente sia inglese che spagnolo.
Un confronto che mostra il modello esistente in difficoltà con lo spagnolo, mentre il nuovo modello trascrive correttamente sia inglese che spagnolo.
2. Ambienti rumorosi
Il problema: Rumore del vento nelle riprese esterne, chiacchiericcio in un bar affollato o annunci in metropolitana spesso sovrastano la voce principale, portando i modelli tradizionali a saltare intere frasi o trascrivere il rumore come parole.
La soluzione del nuovo modello: L’elaborazione audio avanzata isola la voce umana dal rumore di fondo complesso, mantenendo un’elevata precisione anche in ambienti con molto rumore.
📝 Scenario demo: Vlog in una stazione della metro affollata
- Modello esistente: "...sto andando... (rumore incomprensibile) ...stazione oggi."
- Nuovo modello: "Anche se qui è super affollato, sto comunque andando alla stazione oggi."
3. Accenti forti e pronuncia non standard
Il problema: Accenti regionali marcati o non nativi causano spesso un forte calo nella precisione della trascrizione, perché i modelli più vecchi si basano troppo su schemi di pronuncia standard.
La soluzione del nuovo modello: Addestrato su un vasto e diversificato dataset globale, il nuovo modello utilizza una comprensione contestuale superiore per interpretare cosa si intendeva dire, anche se la pronuncia si discosta dallo “standard”.
📝 Scenario demo: Forte accento giapponese che parla inglese (Japanglish)
- Contesto audio: Un parlante pronuncia "McDonald's" con forte influsso fonetico giapponese (es. "Makudonarudo").
- Modello esistente: "Voglio mangiare mark donald road." (interpretazione fonetica errata)
- Nuovo modello: "Voglio mangiare McDonald's." (riconoscimento contestuale)
4. Riconoscimento specializzato del cantonese
Il problema: Il cantonese è una lingua distinta con una sintassi e caratteri specifici che non esistono in mandarino. I modelli generici spesso forzano la trascrizione in omofoni mandarini errati, cambiando completamente il significato.
La soluzione del nuovo modello: Abbiamo incluso una modellazione specializzata per il cantonese, garantendo il riconoscimento accurato della grammatica e dei caratteri locali.
📝 Scenario demo: Conversazione informale in cantonese
- Modello esistente (caratteri mandarini errati): "你依家系度做勿?我好中意食那个。"
- Nuovo modello (corretti caratteri cantonese): "你依家系度做乜?我好钟意食嗰个。"
Come utilizzare il nuovo modello
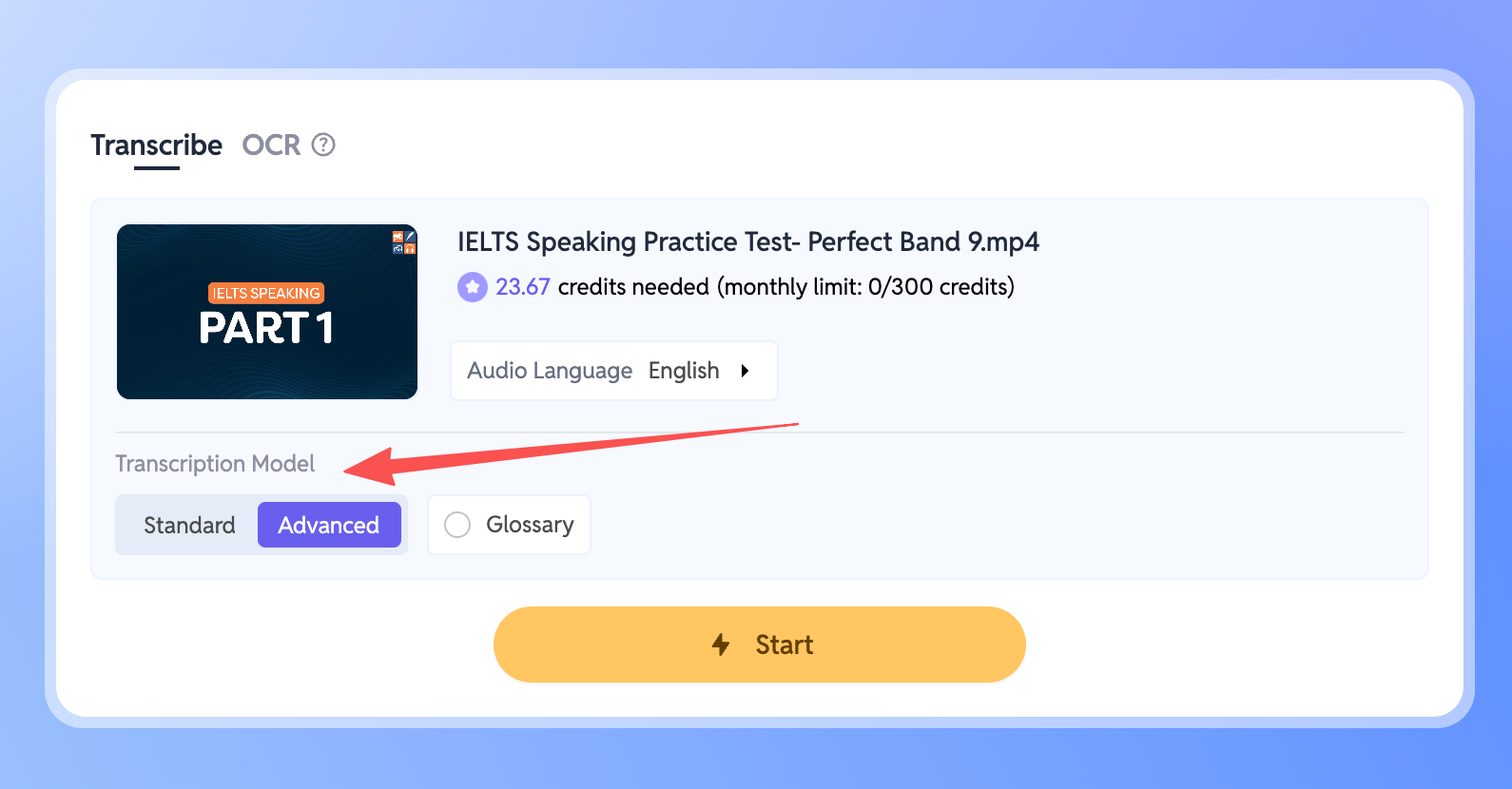
- Vai nel tuo Workspace e seleziona il file che desideri trascrivere.
- Trova l’impostazione Modello di trascrizione nel pannello.
- Basta passare la modalità su Avanzato.
Una volta selezionato, il nuovo modello prenderà automaticamente il controllo, gestendo istantaneamente rumore, accenti o lingue miste nel tuo file.
Conclusione
Precisione significa efficienza. Il nuovo modello di SubEasy è progettato per risolvere quel difficile 5% di audio che rallenta il tuo lavoro—che si tratti di cambi di lingua improvvisi, accenti complessi o ambienti rumorosi.
Vogliamo aiutarti a passare meno tempo a correggere i sottotitoli e più tempo a creare contenuti di qualità. Il nuovo modello è disponibile da provare oggi stesso.