

Введение: Когда ИИ встречается с реальным миром
Любой может расшифровать чистый, студийный звук. Но контент из реального мира — видеоблоги, интервью на выезде, записи на улице — бывает очень «шумным».
Когда говорящий внезапно переходит на другой язык, когда шум дороги заглушает голос или когда у собеседника сильный акцент, традиционные ИИ-модели для транскрипции дают сбой. В результате создателям приходится часами вручную исправлять ошибки.
Сегодня SubEasy с гордостью представляет нашу совершенно новую модель транскрипции. Мы не просто повысили общую точность — мы специально разработали эту модель для решения пяти самых раздражающих сценариев, с которыми сталкиваются создатели контента.
Вот как новая модель проявляет себя на практике.
1. Многоязычная смешанная речь (Code-Switching)
Проблема: В международных бизнес-встречах или современных тревел-влогах говорящие часто переключаются между языками прямо в середине предложения (code-switching). Большинство существующих моделей пытаются транскрибировать всё в одном языке, превращая вторую часть в бессмысленный набор символов.
Решение новой модели: Наша модель мгновенно распознаёт смену языка. Как видно на сравнении ниже, когда спикер переключается с английского на испанский, новая модель без проблем переходит между языками и точно транскрибирует оба.
 Сравнение: старая модель ошибается на испанских фрагментах, новая — точно транскрибирует смешанную речь.
Сравнение: старая модель ошибается на испанских фрагментах, новая — точно транскрибирует смешанную речь.
2. Шумные условия
Проблема: Шум ветра на улице, разговоры в кафе или объявления в метро часто заглушают основного спикера, из-за чего традиционные модели пропускают целые фразы или «понимают» шум как слова.
Решение новой модели: Продвинутые алгоритмы обработки звука отделяют человеческую речь от сложного фонового шума, обеспечивая высокую точность даже в условиях низкого соотношения сигнал/шум.
📝 Демонстрация: Влог на шумной станции метро
- Старая модель: «...going to... (неразборчивый шум) ...station today.»
- Новая модель: «Even though it's super crowded here, I am still going to the station today.»
3. Сильные акценты и нестандартное произношение
Проблема: Сильные региональные или иностранные акценты резко снижают точность транскрипции, так как старые модели слишком зависят от стандартных шаблонов произношения.
Решение новой модели: Обученная на огромном и разнообразном мировом датасете, новая модель использует контекстное понимание, чтобы распознать смысл даже при нестандартном произношении.
📝 Демонстрация: Сильный японский акцент в английском (Japanglish)
- Контекст: Спикер произносит «McDonald's» с сильным японским акцентом («Makudonarudo»).
- Старая модель: «I want to eat mark donald road.» (Фонетическая ошибка)
- Новая модель: «I want to eat McDonald's.» (Контекстное распознавание)
4. Специализированное распознавание кантонского
Проблема: Кантонский — самостоятельный язык с уникальным синтаксисом и специфическими иероглифами, которых нет в мандаринском. Обычные модели часто ошибочно транскрибируют кантонскую речь как мандарин, искажают смысл.
Решение новой модели: Мы внедрили специализированное моделирование для кантонского, чтобы точно распознавать грамматику и локальные символы.
📝 Демонстрация: Неформальный разговор на кантонском
- Старая модель (ошибочные мандаринские иероглифы): «你依家系度做勿?我好中意食那个。」
- Новая модель (правильные кантонские иероглифы): «你依家系度做乜?我好钟意食嗰个。」
Как использовать новую модель
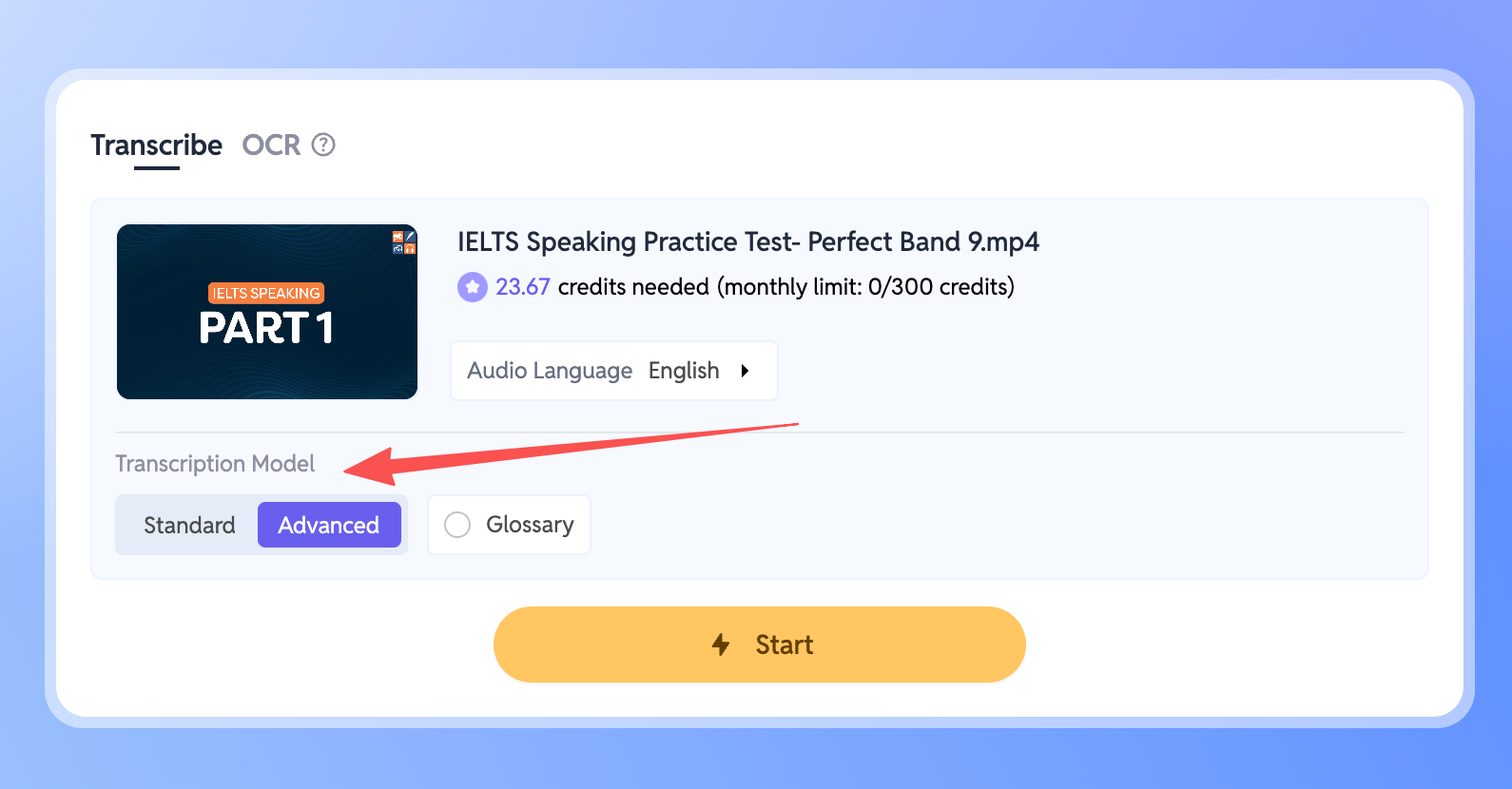
- Зайдите в свой Workspace и выберите файл для транскрипции.
- Найдите настройку Transcription Model в панели.
- Просто переключите режим на Advanced.
После выбора новая модель автоматически начнёт работу, мгновенно обрабатывая шум, акценты и смешанные языки.
Заключение
Точность — это эффективность. Обновлённая модель SubEasy создана, чтобы решить те самые сложные 5% аудио, которые тормозят ваш рабочий процесс — будь то неожиданные языковые переключения, акценты или шумовые помехи.
Мы хотим, чтобы вы меньше времени тратили на исправление субтитров и больше — на создание классного контента. Новая модель уже доступна для тестирования.