

Einführung: Wenn KI auf die reale Welt trifft
Jeder kann klares, im Studio aufgenommenes Audio transkribieren. Doch Inhalte aus dem echten Leben – Vlogs, Interviews vor Ort, Straßenaufnahmen – sind chaotisch.
Wenn ein Sprecher plötzlich die Sprache wechselt, Hintergrundverkehr eine Stimme übertönt oder ein Interviewpartner einen starken Akzent hat, versagen herkömmliche KI-Transkriptionsmodelle. Das zwingt Kreative zu stundenlanger, mühsamer Nachbearbeitung.
Heute stellt SubEasy stolz unser brandneues Transkriptionsmodell vor. Wir haben nicht nur die allgemeine Genauigkeit verbessert, sondern dieses Modell speziell darauf ausgelegt, die fünf frustrierendsten Szenarien für Content-Ersteller zu meistern.
So schlägt sich das neue Modell im Praxistest.
1. Mehrsprachiges, gemischtes Audio (Code-Switching)
Das Problem: In internationalen Geschäftstreffen oder modernen Reise-Vlogs wechseln Sprecher oft mitten im Satz die Sprache (Code-Switching). Die meisten existierenden Modelle zwingen das transkribierte Audio in eine einzige Hauptsprache, sodass die zweite Sprache zu Kauderwelsch wird.
Die Lösung des neuen Modells: Unser neues Modell erkennt Sprachwechsel sofort intelligent. Wie im Vergleich unten zu sehen, bei dem der Sprecher von Englisch zu Spanisch wechselt, transkribiert das neue Modell beide Sprachen nahtlos und korrekt.
 Ein Vergleich, bei dem das bestehende Modell Schwierigkeiten mit den spanischen Segmenten hat, während das neue Modell das gemischte Englisch-Spanisch-Audio korrekt transkribiert.
Ein Vergleich, bei dem das bestehende Modell Schwierigkeiten mit den spanischen Segmenten hat, während das neue Modell das gemischte Englisch-Spanisch-Audio korrekt transkribiert.
2. Geräuschvolle Umgebungen
Das Problem: Windgeräusche bei Außenaufnahmen, geschäftiges Café-Geschnatter oder Durchsagen in der U-Bahn übertönen oft den Hauptsprecher, sodass herkömmliche Modelle ganze Sätze überspringen oder Geräusche als Wörter transkribieren.
Die Lösung des neuen Modells: Fortschrittliche Audioprozesse isolieren menschliche Sprache von komplexen Hintergrundgeräuschen und gewährleisten hohe Genauigkeit selbst bei niedrigem Signal-Rausch-Verhältnis.
📝 Demo-Szenario: Vlog in einer vollen U-Bahnstation
- Bestehendes Modell: "...going to... (unhörbares Geräusch) ...station today."
- Neues Modell: "Even though it's super crowded here, I am still going to the station today."
3. Starke Akzente und nicht standardisierte Aussprache
Das Problem: Starke regionale oder nicht-muttersprachliche Akzente führen oft zu massiven Genauigkeitsverlusten, da ältere Modelle zu sehr auf standardisierte Aussprachen setzen.
Die Lösung des neuen Modells: Trainiert auf einem riesigen, vielfältigen globalen Datensatz, nutzt das neue Modell überlegene kontextuelle Erkennung, um zu verstehen, was gemeint ist – selbst wenn die Aussprache vom „Standard“ abweicht.
📝 Demo-Szenario: Starker japanischer Akzent im Englischen (Japanglish)
- Audio-Kontext: Ein Sprecher spricht „McDonald's“ mit stark japanischer Phonetik (z.B. „Makudonarudo“).
- Bestehendes Modell: "I want to eat mark donald road." (Phonetische Fehlinterpretation)
- Neues Modell: "I want to eat McDonald's." (Kontextuelle Erkennung)
4. Spezialisierte Kantonesisch-Erkennung
Das Problem: Kantonesisch ist eine eigenständige Sprache mit einzigartiger Syntax und speziellen Zeichen, die im Mandarin nicht existieren. Standardmodelle transkribieren Kantonesisch oft fälschlich in Mandarin-Homophone und verändern so die Bedeutung.
Die Lösung des neuen Modells: Wir haben ein spezialisiertes Modell für Kantonesisch integriert, das spezifische Grammatik und lokale Zeichen exakt erkennt.
📝 Demo-Szenario: Lockeres Gespräch auf Kantonesisch
- Bestehendes Modell (falsche Mandarin-Zeichen): "你依家系度做勿?我好中意食那个。"
- Neues Modell (korrekte Kantonesisch-Zeichen): "你依家系度做乜?我好钟意食嗰个。"
So nutzen Sie das neue Modell
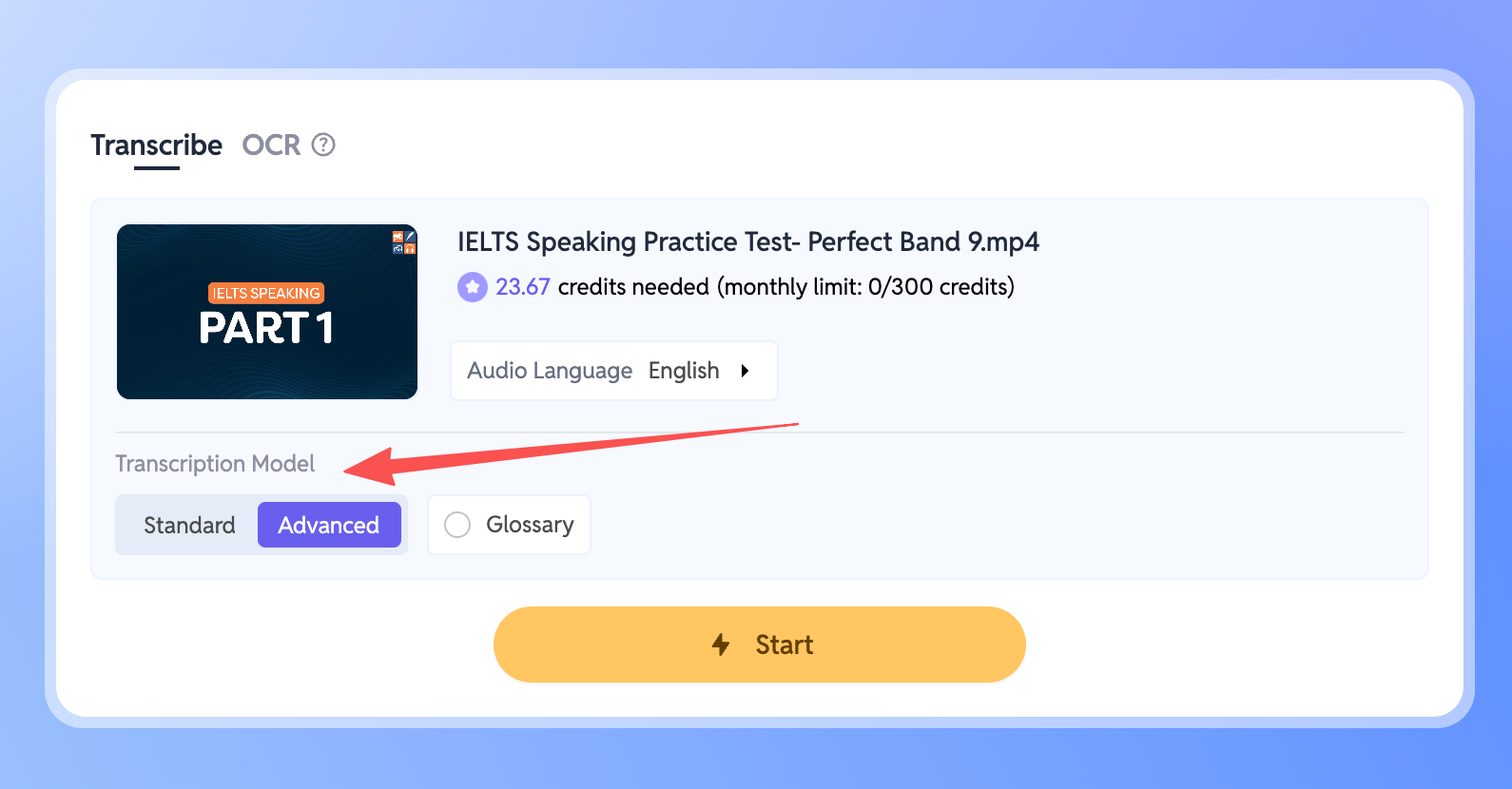
- Gehen Sie in Ihren Workspace und wählen Sie die Datei aus, die Sie transkribieren möchten.
- Suchen Sie in der Seitenleiste die Einstellung Transkriptionsmodell.
- Wechseln Sie einfach in den Modus Erweitert.
Nach der Auswahl übernimmt das neue Modell automatisch und verarbeitet sofort alle Geräusche, Akzente oder gemischten Sprachen in Ihrer Datei.
Fazit
Genauigkeit bedeutet Effizienz. Das neue Modell-Upgrade von SubEasy ist darauf ausgelegt, jene schwierigen 5 % der Audiodaten zu lösen, die Ihren Workflow ausbremsen – egal ob es um unerwartete Sprachwechsel, komplexe Akzente oder laute Umgebungen geht.
Wir möchten, dass Sie weniger Zeit mit der Korrektur von Untertiteln verbringen und mehr Zeit für großartige Inhalte haben. Das neue Modell steht ab sofort zum Testen bereit.