

Introdução: Quando a IA Encontra o Mundo Real
Qualquer pessoa consegue transcrever áudio claro, gravado em estúdio. Mas os conteúdos do mundo real — vlogs, entrevistas em locais movimentados, gravações de rua — são desafiantes.
Quando um orador muda de língua de repente, quando o ruído do trânsito abafa a voz, ou quando um entrevistado tem um sotaque forte, a transcrição automática tradicional falha. Isto obriga os criadores a perderem horas em correções manuais aborrecidas.
Hoje, a SubEasy tem o prazer de apresentar o nosso novo modelo de transcrição. Não melhorámos apenas a precisão geral; este modelo foi especificamente desenvolvido para resolver os cinco cenários mais frustrantes que os criadores enfrentam.
Veja como o novo modelo se comporta na prática.
1. Áudio Multilingue Misturado (Mudança de Código)
O Problema: Em reuniões internacionais ou vlogs de viagem modernos, os oradores mudam frequentemente de língua a meio da frase (code-switching). A maioria dos modelos existentes força a transcrição para uma única língua principal, transformando a secundária em texto sem sentido.
A Solução do Novo Modelo: O nosso novo modelo deteta mudanças de língua instantaneamente. Como se vê na comparação abaixo, onde o orador passa do inglês para o espanhol, o novo modelo faz a transição de forma fluida e capta ambas as línguas com precisão.
 Comparação onde o modelo antigo falha nos segmentos em espanhol, enquanto o novo transcreve corretamente o áudio misto em inglês e espanhol.
Comparação onde o modelo antigo falha nos segmentos em espanhol, enquanto o novo transcreve corretamente o áudio misto em inglês e espanhol.
2. Ambientes Ruidosos
O Problema: Ruído do vento em filmagens exteriores, conversas de café movimentado ou anúncios no metro podem sobrepor-se à voz principal, levando os modelos tradicionais a ignorar frases inteiras ou a transcrever ruído como palavras.
A Solução do Novo Modelo: O processamento avançado de áudio isola a fala humana do ruído de fundo complexo, mantendo elevada precisão mesmo em ambientes com baixo rácio sinal-ruído.
📝 Cenário de Demonstração: Vlog numa estação de metro movimentada
- Modelo Antigo: "...going to... (ruído inaudível) ...station today."
- Novo Modelo: "Even though it's super crowded here, I am still going to the station today."
3. Sotaques Fortes e Pronúncia Não Padrão
O Problema: Sotaques regionais ou de falantes não nativos provocam grandes quebras na precisão da transcrição, pois os modelos antigos dependem demasiado da pronúncia padrão.
A Solução do Novo Modelo: Treinado com um vasto e diverso conjunto de dados global, o novo modelo utiliza compreensão contextual avançada para perceber o que foi dito, mesmo que a pronúncia se afaste do “padrão”.
📝 Cenário de Demonstração: Sotaque japonês forte a falar inglês (Japanglish)
- Contexto de Áudio: Orador pronuncia "McDonald's" com forte influência fonética japonesa (ex.: "Makudonarudo").
- Modelo Antigo: "I want to eat mark donald road." (interpretação fonética errada)
- Novo Modelo: "I want to eat McDonald's." (reconhecimento contextual)
4. Reconhecimento Especializado de Cantonês
O Problema: O cantonês é uma língua distinta, com sintaxe única e caracteres específicos que não existem no mandarim. Os modelos genéricos transcrevem frequentemente áudio cantonês para homófonos errados em mandarim, alterando totalmente o significado.
A Solução do Novo Modelo: Incluímos modelação especializada para cantonês, garantindo o reconhecimento correto da gramática e dos caracteres locais do cantonês.
📝 Cenário de Demonstração: Conversa casual em cantonês
- Modelo Antigo (caracteres errados em mandarim): "你依家系度做勿?我好中意食那个。"
- Novo Modelo (caracteres corretos em cantonês): "你依家系度做乜?我好钟意食嗰个。"
Como Usar o Novo Modelo
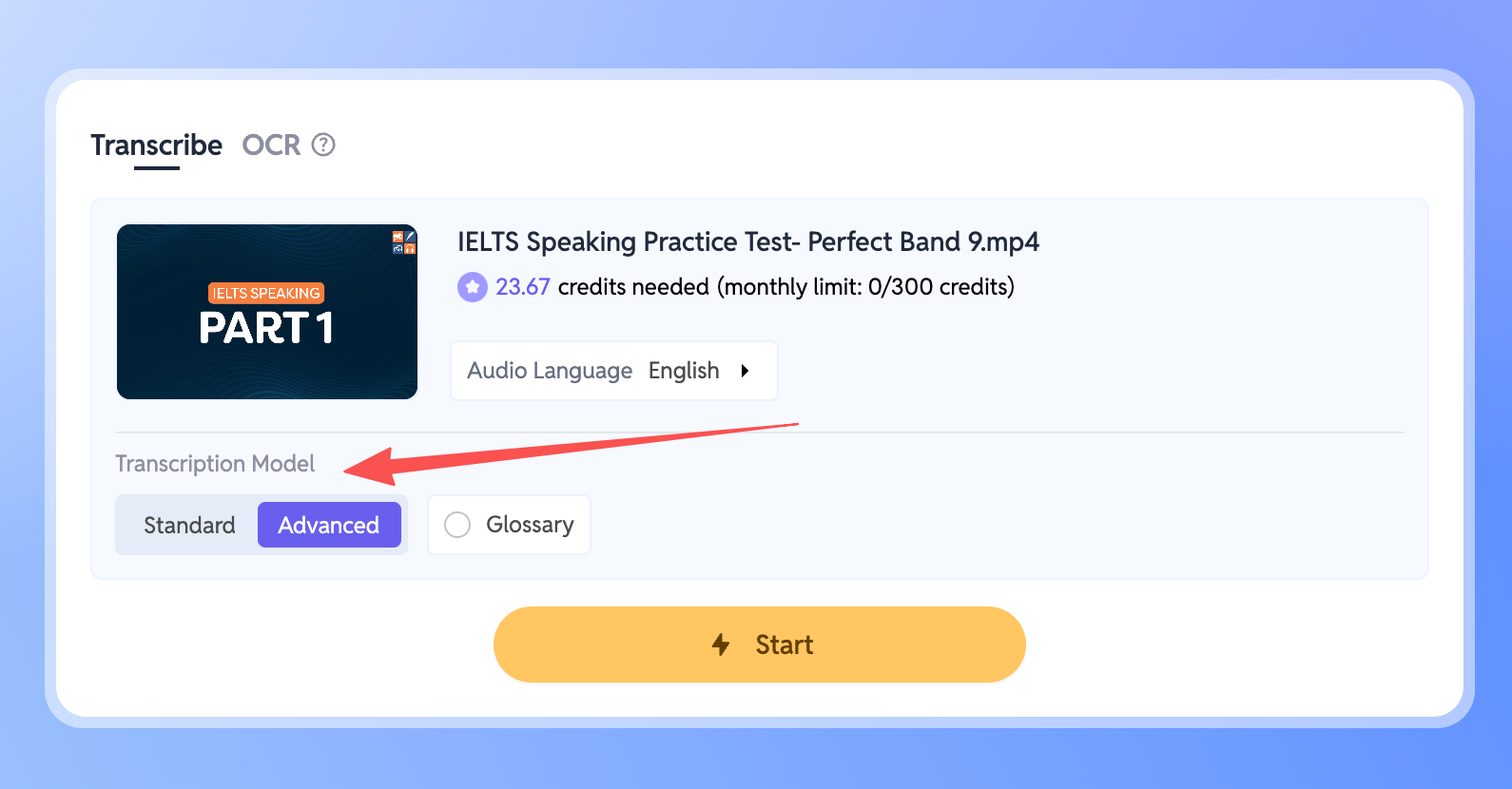
- Vá à sua Área de Trabalho e selecione o ficheiro que deseja transcrever.
- Localize a opção Modelo de Transcrição no painel.
- Basta mudar para o modo Avançado.
Depois de selecionado, o novo modelo assume automaticamente, lidando com ruído, sotaques ou línguas misturadas no seu ficheiro de imediato.
Conclusão
Precisão é eficiência. A nova atualização do modelo SubEasy foi criada para resolver aquele 5% de áudio difícil que atrasa o seu trabalho — seja mudanças inesperadas de língua, sotaques complexos ou ambientes ruidosos.
Queremos que dedique menos tempo a corrigir legendas e mais tempo a criar conteúdos excelentes. O novo modelo está disponível para experimentar hoje.