

简介:当 AI 遇上真实世界
任何人都可以转录清晰、录音室级别的音频。但现实中的内容——Vlog、现场采访、街头录音——往往十分混乱。
当说话人突然切换语言、背景的车流声盖过了人声,或者受访者带有浓重口音时,传统的 AI 转录模型就会“崩溃”。这迫使内容创作者不得不花费数小时手动校正。
**今天,SubEasy 自豪地推出全新升级的转录模型。**我们不仅提升了整体准确率,更是针对创作者们最头疼的四大场景进行了专项优化。
以下是新模型在实际测试中的表现。
1. 多语言混合音频(语言切换)
痛点: 在国际商务会议或现代旅游 Vlog 中,说话人常常在一句话中切换语言(Code-Switching)。大多数现有模型会把音频强行转录为单一主语言,导致次要语言内容变成乱码。
新模型解决方案: 我们的新模型能够智能、即时地检测语言切换。如下面的对比所示,当说话人从英语切换到西班牙语时,新模型可以无缝切换并准确转录两种语言。
 对比图显示旧模型无法正确转录西班牙语片段,而新模型能准确转录混合的英西音频。
对比图显示旧模型无法正确转录西班牙语片段,而新模型能准确转录混合的英西音频。
2. 嘈杂环境
痛点: 室外风声、咖啡馆的嘈杂、地铁广播等背景噪音常常盖过主讲人,传统模型要么跳过整句话,要么把噪声当作词语转录出来。
新模型解决方案: 先进的音频处理技术能够将人声从复杂的背景噪音中分离出来,即使在信噪比极低的环境下也能保持高准确率。
📝 演示场景:繁忙地铁站 vlog
- 旧模型: "...going to... (inaudible noise) ...station today."
- 新模型: "Even though it's super crowded here, I am still going to the station today."
3. 浓重口音与非标准发音
痛点: 浓重的地方口音或非母语者的发音,常让旧模型准确率大幅下降,因为旧模型过于依赖标准发音。
新模型解决方案: 新模型基于海量多元的全球数据集训练,具备更强的上下文理解能力,即使发音偏离“标准”,也能准确识别说话内容。
📝 演示场景:日式英语口音(Japanglish)
- 音频内容: 说话人用浓重日语发音说 "McDonald's"(如 "Makudonarudo")。
- 旧模型: "I want to eat mark donald road."(发音误判)
- 新模型: "I want to eat McDonald's."(语境识别)
4. 粤语专项识别
痛点: 粤语是一种独立语言,语法和用字与普通话完全不同。通用模型常把粤语强行转成普通话同音字,导致意思完全改变。
新模型解决方案: 我们针对粤语进行了专项建模,确保模型能准确识别粤语独有的语法和本地化用字。
📝 演示场景:粤语日常对话
- 旧模型(错误的普通话字符): "你依家系度做勿?我好中意食那个。"
- 新模型(正确的粤语字符): "你依家系度做乜?我好钟意食嗰个。"
如何使用新模型
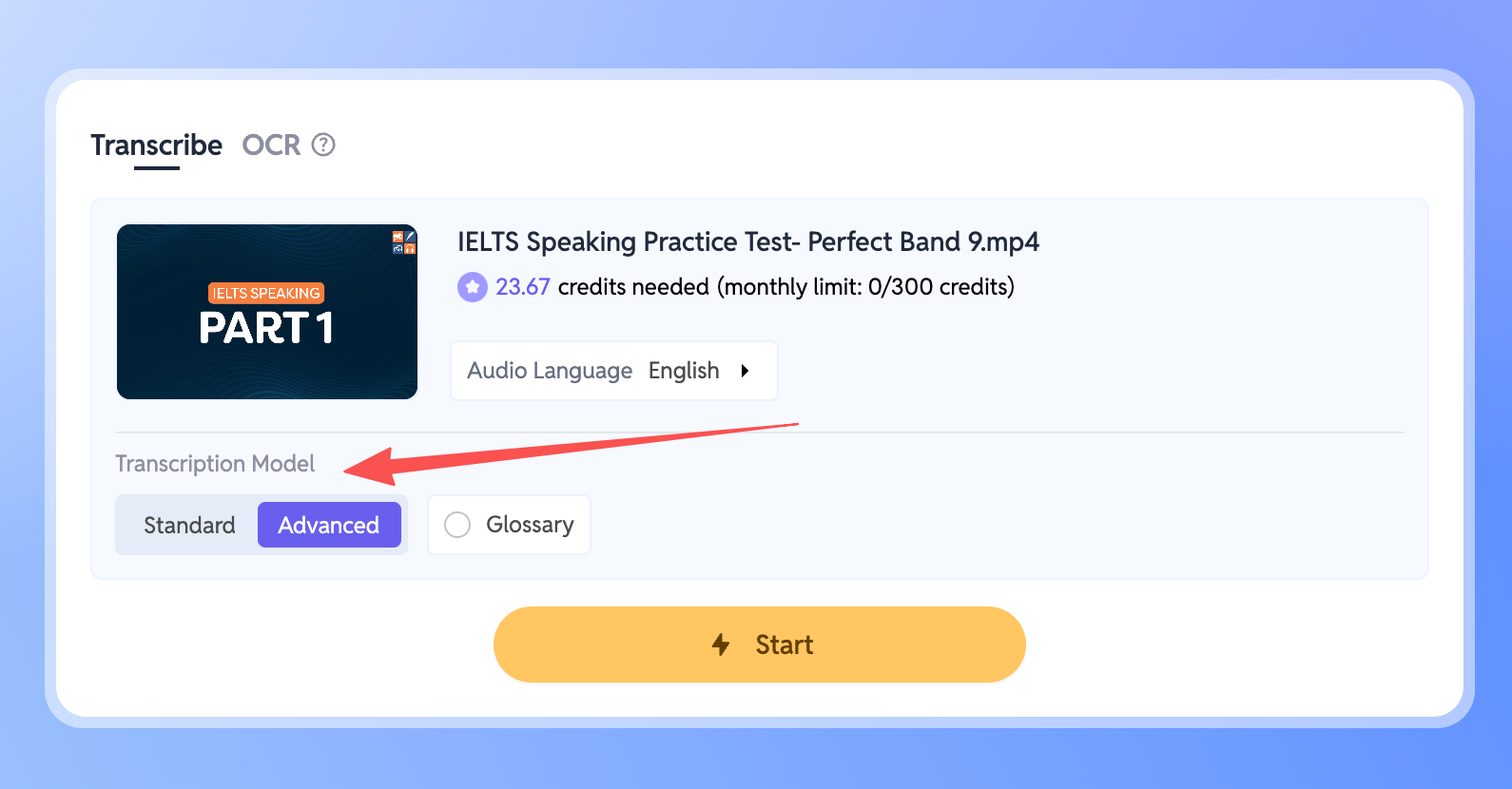
- 进入你的工作区,选择你想转录的文件。
- 在侧边栏找到转录模型设置。
- 切换到高级模式。
选择后,新模型会自动接管,无论是噪音、口音还是多语言混合,都会即时处理。
总结
准确率就是效率。SubEasy 新模型专为解决那 5% 最难搞的音频而设计——无论是突发语言切换、复杂口音还是嘈杂环境。
我们希望你能把更多时间用在创作优质内容上,而不是修字幕。新模型现已上线,欢迎体验!