

Introduction : Quand l’IA rencontre le monde réel
N’importe qui peut transcrire un audio clair et enregistré en studio. Mais le contenu du monde réel — vlogs, interviews sur le terrain, enregistrements de rue — est bien plus complexe.
Quand un interlocuteur change soudainement de langue, quand le bruit de la circulation couvre une voix, ou quand un interviewé a un fort accent, les systèmes de transcription traditionnels échouent. Les créateurs se retrouvent alors à corriger manuellement leurs fichiers pendant des heures.
Aujourd’hui, SubEasy est fier de présenter son tout nouveau modèle de transcription. Nous n’avons pas seulement amélioré la précision générale ; nous avons spécifiquement conçu ce modèle pour résoudre les cinq scénarios les plus frustrants auxquels les créateurs sont confrontés.
Voici comment le nouveau modèle se comporte lors de tests concrets.
1. Audio multilingue et alternance de langues (Code-switching)
Problème rencontré : Dans les réunions internationales ou les vlogs de voyage modernes, les intervenants passent souvent d’une langue à l’autre en cours de phrase (code-switching). La plupart des modèles existants forcent la transcription dans une langue principale, transformant la langue secondaire en charabia.
Solution du nouveau modèle : Notre nouveau modèle détecte instantanément les changements de langue. Comme le montre la comparaison ci-dessous, où l’orateur passe de l’anglais à l’espagnol, le nouveau modèle effectue la transition de façon fluide et retranscrit les deux langues avec précision.
 Comparaison montrant l’ancien modèle en difficulté sur les segments en espagnol, alors que le nouveau modèle retranscrit parfaitement l’audio mêlant anglais et espagnol.
Comparaison montrant l’ancien modèle en difficulté sur les segments en espagnol, alors que le nouveau modèle retranscrit parfaitement l’audio mêlant anglais et espagnol.
2. Environnements bruyants
Problème rencontré : Le bruit du vent lors de prises de vue extérieures, les bavardages dans un café ou les annonces dans le métro couvrent souvent la voix principale, poussant les modèles traditionnels à ignorer des phrases entières ou à transcrire le bruit comme des mots.
Solution du nouveau modèle : Un traitement audio avancé isole la voix humaine des bruits de fond complexes, garantissant une grande précision même dans des environnements où le signal est faible par rapport au bruit.
📝 Scénario démo : Vlog dans une station de métro bondée
- Ancien modèle : "...going to... (bruit inaudible) ...station today."
- Nouveau modèle : "Even though it's super crowded here, I am still going to the station today."
3. Accents forts et prononciations non standard
Problème rencontré : Les accents régionaux marqués ou les accents non natifs font chuter la précision des transcriptions, les anciens modèles s’appuyant trop sur des schémas de prononciation standard.
Solution du nouveau modèle : Entraîné sur un vaste ensemble de données mondiales et diversifiées, le nouveau modèle utilise une compréhension contextuelle avancée pour décoder le sens, même si la prononciation s’écarte de la norme.
📝 Scénario démo : Accent japonais prononçant l’anglais (Japanglish)
- Contexte audio : Un intervenant prononce "McDonald's" avec une forte influence phonétique japonaise (ex. "Makudonarudo").
- Ancien modèle : "I want to eat mark donald road." (Erreur phonétique)
- Nouveau modèle : "I want to eat McDonald's." (Reconnaissance contextuelle)
4. Reconnaissance spécialisée du cantonais
Problème rencontré : Le cantonais est une langue distincte avec une syntaxe et des caractères spécifiques qui n’existent pas en mandarin. Les modèles génériques transcrivent souvent le cantonais en homophones mandarins incorrects, changeant totalement le sens.
Solution du nouveau modèle : Nous avons intégré une modélisation spécialisée pour le cantonais, garantissant la reconnaissance précise de la grammaire et des caractères locaux cantonais.
📝 Scénario démo : Conversation informelle en cantonais
- Ancien modèle (caractères mandarins incorrects) : "你依家系度做勿?我好中意食那个。"
- Nouveau modèle (caractères cantonais corrects) : "你依家系度做乜?我好钟意食嗰个。"
Comment utiliser le nouveau modèle
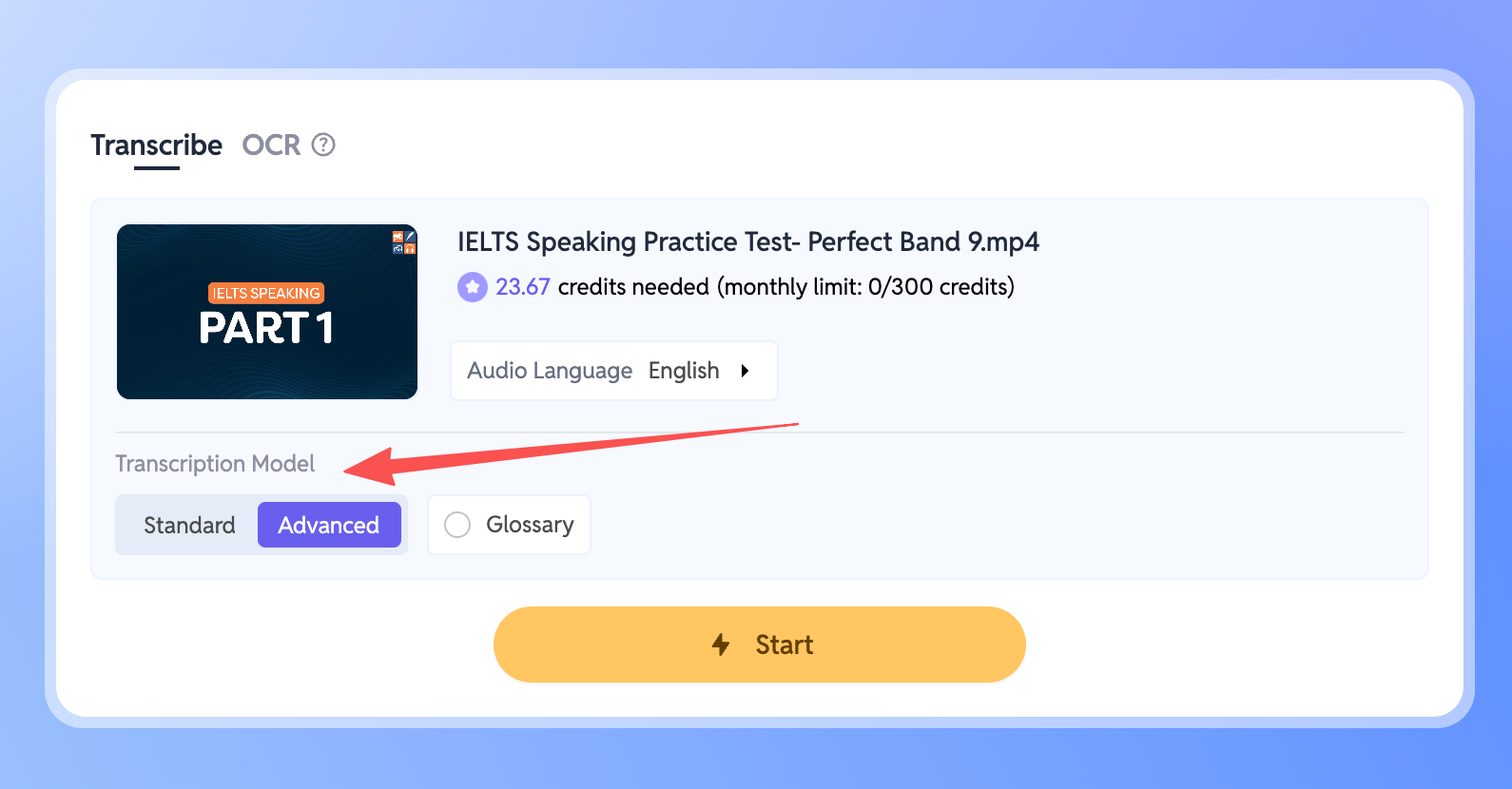
- Rendez-vous dans votre Espace de travail et choisissez le fichier à transcrire.
- Trouvez le paramètre Modèle de transcription dans le panneau.
- Passez simplement le mode sur Avancé.
Une fois sélectionné, le nouveau modèle prend automatiquement le relais et gère instantanément le bruit, les accents ou les langues mélangées dans votre fichier.
Conclusion
La précision, c’est l’efficacité. La mise à jour du modèle de SubEasy est conçue pour résoudre ces 5% d’audios complexes qui ralentissent votre flux de travail — qu’il s’agisse de changements de langue inattendus, d’accents marqués ou d’environnements bruyants.
Nous voulons vous aider à passer moins de temps à corriger des sous-titres et plus de temps à créer du contenu de qualité. Le nouveau modèle est disponible dès aujourd’hui.