

소개: AI가 현실 세계를 만날 때
누구나 스튜디오급의 깨끗한 오디오는 쉽게 전사할 수 있습니다. 하지만 실제 콘텐츠—브이로그, 현장 인터뷰, 거리 녹음—는 혼란스럽고 복잡합니다.
화자가 갑자기 언어를 바꾸거나, 도로 소음이 목소리를 덮거나, 인터뷰이가 강한 억양을 가지고 있다면 기존의 AI 전사기는 제대로 작동하지 않습니다. 결국 크리에이터는 수 시간에 걸친 지루한 수작업 수정에 시달리게 됩니다.
오늘, SubEasy는 완전히 새로워진 전사 모델을 자랑스럽게 소개합니다. 단순히 전체적인 정확도를 높이는 데 그치지 않고, 크리에이터들이 가장 답답해하는 4 가지 상황을 집중적으로 해결하도록 설계했습니다.
새 모델이 실제 상황에서 어떻게 성능을 발휘하는지 지금 확인해보세요.
1. 다국어 혼합 오디오 (코드 스위칭)
문제점:
국제 비즈니스 미팅이나 여행 브이로그 등에서는 화자가 한 문장 안에서도 언어를 자주 바꿉니다(코드 스위칭). 기존 모델은 오디오를 한 가지 주 언어로만 전사하려 해, 다른 언어는 엉뚱한 글자로 처리해버립니다.
새 모델의 해결책:
새 모델은 언어 전환을 즉각적으로 감지합니다. 아래 비교 예시처럼, 화자가 영어에서 스페인어로 바꿔 말할 때도 자연스럽고 정확하게 둘 다 전사합니다.

기존 모델이 스페인어 구간에서 어려움을 겪는 반면, 새 모델은 영어와 스페인어 모두 정확하게 전사하는 모습.
2. 시끄러운 환경
문제점:
야외 촬영의 바람 소리, 북적이는 카페의 대화, 지하철 안내방송 등은 화자의 목소리를 덮어버려 기존 모델이 문장을 통째로 빼먹거나 소음을 단어로 인식하게 만듭니다.
새 모델의 해결책:
고급 오디오 처리 기술로 복잡한 배경 소음 속에서도 사람의 목소리를 분리하여, 신호대잡음비가 낮은 환경에서도 높은 정확도를 유지합니다.
📝 데모 시나리오: 붐비는 지하철역 브이로그
- 기존 모델: "...going to... (들리지 않는 소음) ...station today."
- 새 모델: "Even though it's super crowded here, I am still going to the station today."
3. 강한 억양 및 비표준 발음
문제점:
강한 지역 억양이나 비원어민 발음은 기존 모델이 표준 발음에만 의존해 전사 정확도가 크게 떨어집니다.
새 모델의 해결책:
전 세계의 다양한 데이터셋으로 학습되어, 발음이 표준과 달라도 문맥을 파악해 ‘의미’를 정확히 이해하고 전사합니다.
📝 데모 시나리오: 일본식 영어 억양(Japanglish)
- 오디오 상황: "McDonald's"를 일본식 발음(예: "Makudonarudo")으로 말함
- 기존 모델: "I want to eat mark donald road." (발음 오해)
- 새 모델: "I want to eat McDonald's." (문맥 인식)
4. 광둥어 특화 인식
문제점:
광둥어는 만다린과 문법, 문자 체계가 달라, 일반 모델은 광둥어를 만다린의 비슷한 음으로 억지로 전사해 의미를 왜곡합니다.
새 모델의 해결책:
광둥어 전용 모델링을 적용해, 광둥어만의 문법과 지역어를 정확히 인식합니다.
📝 데모 시나리오: 일상 광둥어 대화
- 기존 모델(잘못된 만다린 문자): "你依家系度做勿?我好中意食那个。"
- 새 모델(정확한 광둥어 문자): "你依家系度做乜?我好钟意食嗰个。"
새 모델 사용 방법
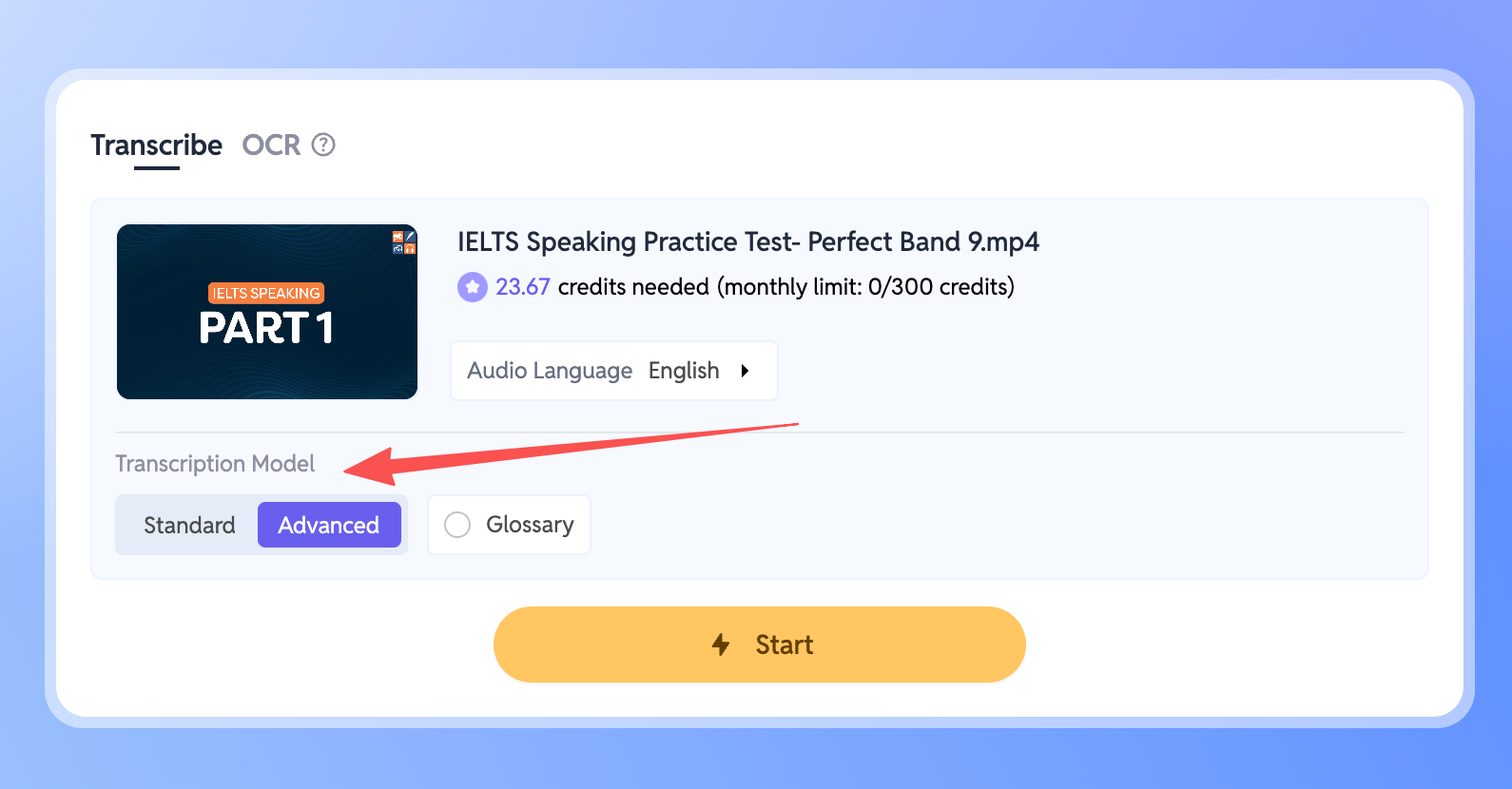
- 워크스페이스로 이동하여 전사할 파일을 선택합니다.
- 패널에서 Transcription Model(전사 모델) 설정을 찾으세요.
- 모드를 Advanced(고급)로 변경하면 됩니다.
선택 즉시 새 모델이 적용되어, 파일 속의 소음, 억양, 다국어 전환도 자동으로 처리합니다.
결론
정확도가 곧 효율입니다. SubEasy의 새 모델은 언어 전환, 복잡한 억양, 시끄러운 배경 등 작업을 느리게 만드는 까다로운 5%의 오디오 문제를 해결하기 위해 탄생했습니다.
이제 자막 수정에 시간을 쓰지 말고, 더 멋진 콘텐츠 제작에 집중하세요. 새 모델을 지금 바로 경험해보세요.