

Introducción: Cuando la IA se enfrenta al mundo real
Cualquiera puede transcribir audio claro y de calidad de estudio. Pero el contenido del mundo real—vlogs, entrevistas en exteriores, grabaciones en la calle—es mucho más complicado.
Cuando un hablante cambia de idioma de repente, cuando el tráfico de fondo ahoga la voz o cuando una persona entrevistada tiene un acento muy marcado, la transcripción automática tradicional falla. Esto obliga a los creadores a dedicar horas a corregir manualmente los errores.
Hoy, en SubEasy estamos orgullosos de presentar nuestro nuevo modelo de transcripción. No solo hemos mejorado la precisión general; hemos diseñado este modelo específicamente para afrontar los 4 escenarios más frustrantes a los que se enfrentan los creadores.
Así es como se comporta el nuevo modelo cuando lo ponemos a prueba.
1. Audio Multilingüe Mixto (Code-Switching)
El problema:
En reuniones internacionales de negocios o en vlogs de viajes modernos, los hablantes suelen cambiar de idioma a mitad de frase (code-switching). La mayoría de los modelos existentes fuerzan la transcripción en un solo idioma principal, convirtiendo el secundario en un galimatías.
La solución del nuevo modelo:
Nuestro nuevo modelo detecta los cambios de idioma al instante. Como se ve en la comparación a continuación, donde el hablante cambia de inglés a español, el nuevo modelo transcribe ambos idiomas de manera precisa y fluida.

Comparación donde el modelo anterior tiene dificultades con los segmentos en español, mientras que el nuevo modelo transcribe correctamente el audio mixto en inglés y español.
2. Entornos Ruidosos
El problema:
El ruido del viento en exteriores, el bullicio de una cafetería o los anuncios en el metro suelen tapar al hablante principal, haciendo que los modelos tradicionales omitan frases enteras o confundan el ruido con palabras.
La solución del nuevo modelo:
El procesamiento avanzado de audio aísla la voz humana del ruido de fondo complejo, manteniendo una alta precisión incluso en entornos con baja relación señal/ruido.
📝 Escenario de demostración: Vlog en una estación de metro concurrida
- Modelo anterior: "...voy a... (ruido inaudible) ...estación hoy."
- Nuevo modelo: "Aunque está súper lleno aquí, igual voy a la estación hoy."
3. Acentos Fuertes y Pronunciación No Estándar
El problema:
Los acentos regionales marcados o los hablantes no nativos suelen provocar grandes caídas en la precisión de la transcripción, ya que los modelos antiguos dependen demasiado de los patrones de pronunciación estándar.
La solución del nuevo modelo:
Entrenado con un amplio y diverso conjunto de datos globales, el nuevo modelo utiliza una comprensión contextual avanzada para descifrar lo que se quiso decir, incluso si la pronunciación se aleja de la "estándar".
📝 Escenario de demostración: Fuerte acento japonés hablando inglés ("Japanglish")
- Contexto de audio: Un hablante pronuncia "McDonald's" con fuerte influencia fonética japonesa (por ejemplo, "Makudonarudo").
- Modelo anterior: "I want to eat mark donald road." (Interpretación fonética errónea)
- Nuevo modelo: "I want to eat McDonald's." (Reconocimiento contextual)
4. Reconocimiento Especializado de Cantonés
El problema:
El cantonés es un idioma distinto, con sintaxis y caracteres específicos que no existen en mandarín. Los modelos genéricos suelen forzar la transcripción al mandarín, cambiando completamente el significado.
La solución del nuevo modelo:
Hemos incorporado un modelado especializado para cantonés, garantizando el reconocimiento preciso de la gramática y los caracteres localizados propios del idioma.
📝 Escenario de demostración: Conversación casual en cantonés
- Modelo anterior (caracteres erróneos en mandarín): "你依家系度做勿?我好中意食那个。"
- Nuevo modelo (caracteres correctos en cantonés): "你依家系度做乜?我好钟意食嗰个。"
Cómo usar el nuevo modelo
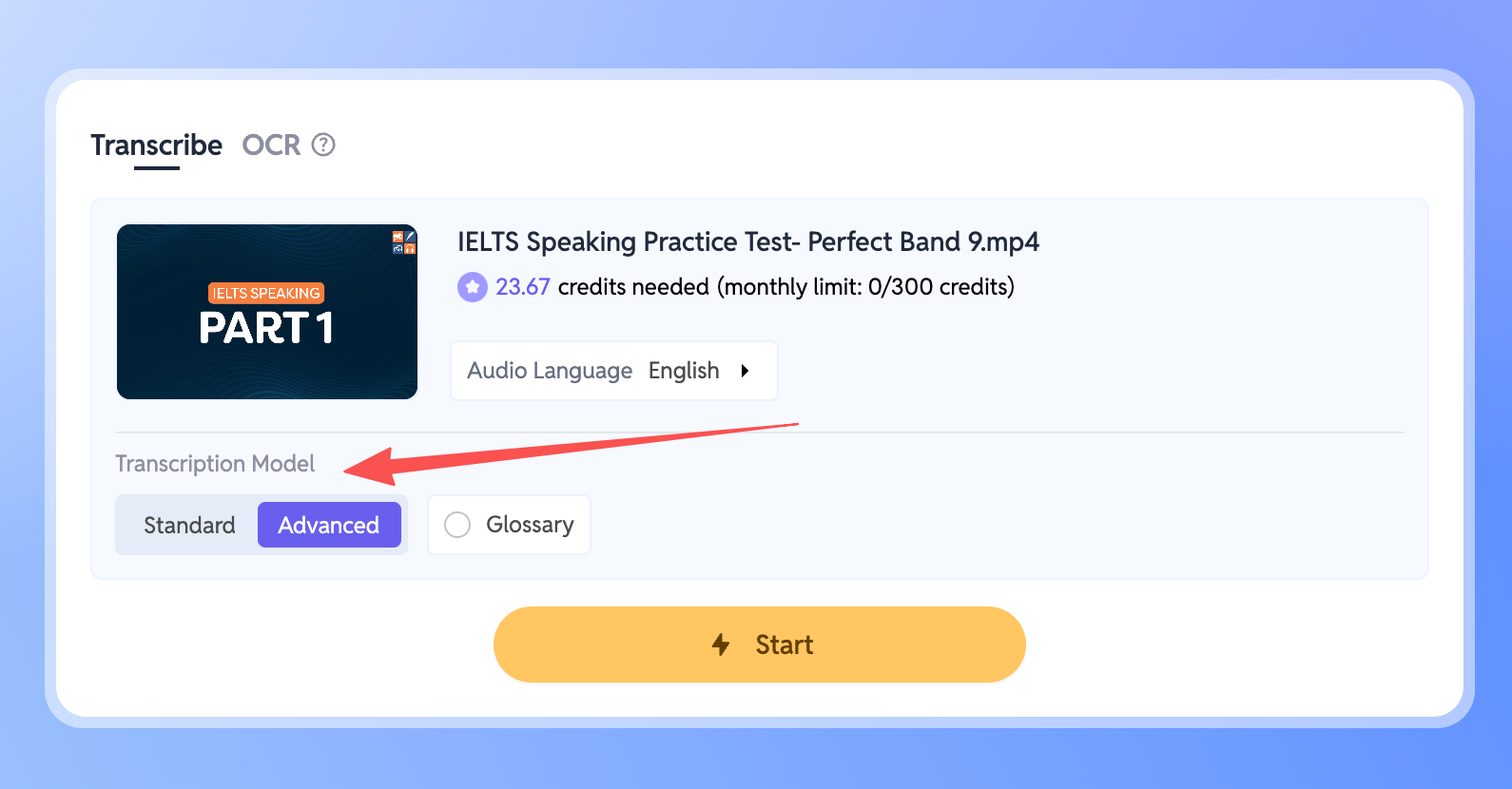
- Accede a tu Workspace y selecciona el archivo que deseas transcribir.
- Busca el ajuste Modelo de Transcripción en el panel.
- Cambia el modo a Avanzado.
Una vez seleccionado, el nuevo modelo se activará automáticamente y gestionará cualquier ruido, acento o mezcla de idiomas en tu archivo al instante.
Conclusión
La precisión es eficiencia. La nueva actualización del modelo de SubEasy está diseñada para resolver ese 5% más difícil del audio que ralentiza tu flujo de trabajo—ya sean cambios inesperados de idioma, acentos complejos o entornos ruidosos.
Queremos ayudarte a dedicar menos tiempo corrigiendo subtítulos y más tiempo creando contenido de calidad. El nuevo modelo ya está disponible para que lo pruebes hoy mismo.