

Here is your translation into Japanese (ja-JP):
はじめに:AIが現実世界と出会うとき
誰でもクリアなスタジオ品質の音声を文字起こしできます。しかし、現実のコンテンツ――Vlogや現地インタビュー、街中の録音――はそう簡単ではありません。
話者が突然言語を切り替えたり、交通音が声をかき消したり、インタビュー相手が強いアクセントを持っていたりすると、従来のAI文字起こしはうまく機能しなくなります。その結果、クリエイターは何時間も手作業で修正するはめになります。
SubEasyは本日、まったく新しい文字起こしモデルを発表します。
一般的な精度を向上させただけでなく、クリエイターが直面する最も厄介な4つのシナリオに特化して設計しました。
新モデルが実際にどのように機能するか、ご紹介します。
1. 多言語混在音声(コードスイッチング)
課題:
国際会議や現代の旅行Vlogでは、話者が文中で言語を切り替えること(コードスイッチング)がよくあります。従来のモデルでは、音声を強制的に一つの主要言語に変換し、二次言語部分は意味不明な文字になってしまいます。
新モデルの解決策:
新モデルは言語の切り替えを即座に検知し、英語からスペイン語へのスイッチなども、両方を正確に文字起こしします。

従来モデルがスペイン語部分で苦戦しているのに対し、新モデルは英語とスペイン語の混在音声を正確に文字起こししています。
2. 騒がしい環境
課題:
屋外の風音、カフェの雑談、地下鉄のアナウンスなどが主音声をかき消し、従来モデルではフレーズが抜けたり、ノイズを単語として誤認したりします。
新モデルの解決策:
高度な音声処理により、人の声を複雑な背景ノイズから分離し、低S/N環境でも高い精度を維持します。
📝 デモシナリオ:混雑した地下鉄駅でのVlog
- 従来モデル: 「…going to…(聞き取れないノイズ)…station today.」
- 新モデル: 「Even though it's super crowded here, I am still going to the station today.」
3. 強いアクセントや非標準発音
課題:
強い地域アクセントや非ネイティブの発音では、従来モデルは標準発音に頼りすぎて精度が大きく低下します。
新モデルの解決策:
多様なグローバルデータセットで学習し、優れた文脈理解によって、発音が「標準」と異なっていても意味を正確に把握します。
📝 デモシナリオ:日本語アクセントの強い英語(ジャパングリッシュ)
- 音声例: 「McDonald's」を日本語風に「マクドナルド」と発音。
- 従来モデル: 「I want to eat mark donald road.」(発音の誤認)
- 新モデル: 「I want to eat McDonald's.」(文脈認識)
4. 広東語の専門認識
課題:
広東語は独自の文法と文字を持ち、普通話(マンダリン)とは異なります。汎用モデルでは広東語音声を誤って普通話の同音異義語に変換し、意味が変わってしまいます。
新モデルの解決策:
広東語専用のモデルを導入し、広東語特有の文法やローカル文字を正確に認識します。
📝 デモシナリオ:カジュアルな広東語会話
- 従来モデル(誤った普通話の文字): 「你依家系度做勿?我好中意食那个。」
- 新モデル(正しい広東語の文字): 「你依家系度做乜?我好钟意食嗰个。」
新モデルの使い方
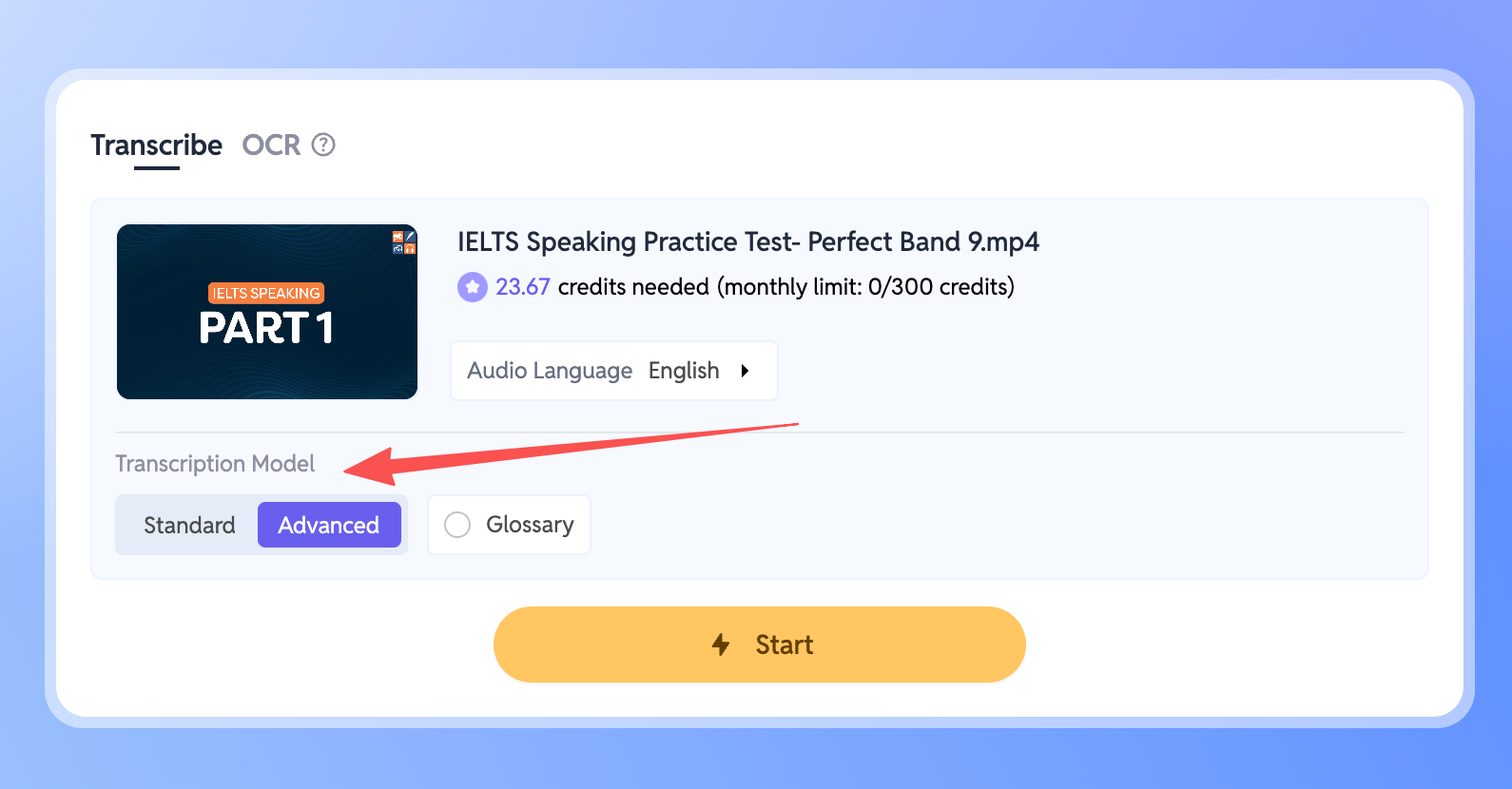
- ワークスペースに移動し、文字起こししたいファイルを選択します。
- パネル内の文字起こしモデル設定を探します。
- モードを高度に切り替えるだけです。
選択すると、新モデルが自動的に作動し、ノイズ、アクセント、混在言語を即座に処理します。
結論
精度は効率に直結します。SubEasyの新モデルは、ワークフローを遅らせる厄介な5%の音声――予期しない言語切り替え、複雑なアクセント、騒がしい背景――を解決するために設計されています。
字幕修正に費やす時間を減らし、より良いコンテンツ制作に集中できるようサポートします。新モデルは本日よりお試しいただけます。