

當 AI 遇上真實世界
任何人都能轉錄清晰、錄音室等級的音訊,但真實世界的內容——像是 Vlog、現場採訪、街頭錄音——往往很混亂。
當講者突然切換語言、背景車流淹沒了聲音,或受訪者口音很重時,傳統 AI 轉錄就會失靈,讓創作者不得不花上數小時手動修正。
今天,SubEasy 隆重推出全新轉錄模型。 我們不只提升了整體準確率,更專門針對創作者最頭痛的四大情境進行了技術突破。
以下是新模型在各種挑戰下的表現。
1. 多語混合音訊(語言切換)
痛點: 在國際商務會議或現代旅遊 Vlog 中,講者常常一句話裡就切換語言(Code-Switching)。多數現有模型只會強行把音訊歸類到一種主要語言,導致次要語言被錯誤轉錄成亂碼。
新模型解決方案: 我們的新模型能即時偵測語言切換。如下圖所示,當講者從英文切換到西班牙文,新模型能無縫轉換,準確地轉錄兩種語言。
 比較圖:舊模型無法正確處理西班牙文片段,新模型則精準轉錄英西混合音訊。
比較圖:舊模型無法正確處理西班牙文片段,新模型則精準轉錄英西混合音訊。
2. 嘈雜環境
痛點: 戶外風聲、咖啡館人聲、地鐵廣播等常常蓋過主要講者,傳統模型不但會跳漏整句話,有時甚至把噪音誤認成語音。
新模型解決方案: 先進的音訊處理技術能有效分離人聲與複雜背景噪音,即使在低訊噪比環境下也能保持高準確率。
📝 示範場景:繁忙地鐵站 Vlog
- 舊模型: "...going to...(雜音無法辨識)...station today."
- 新模型: "Even though it's super crowded here, I am still going to the station today."
3. 強烈口音及非標準發音
痛點: 強烈的地方或非母語口音會讓舊模型準確率大幅下降,因為它們過度依賴標準發音模式。
新模型解決方案: 新模型訓練於全球多元資料集,能以更優秀的語境理解能力,正確解讀「意思」,即使發音與標準差異很大也沒問題。
📝 示範場景:日本腔英文(Japanglish)
- 音訊內容: 講者以日語發音說 "McDonald's"(如 "Makudonarudo")。
- 舊模型: "I want to eat mark donald road."(音譯錯誤)
- 新模型: "I want to eat McDonald's."(語境識別正確)
4. 粵語專屬識別
痛點: 粵語有獨特語法和字詞,與普通話完全不同。一般模型常把粵語音訊誤轉成錯誤的普通話同音字,意思全變了。
新模型解決方案: 我們針對粵語進行了專項建模,能正確識別粵語語法及在地字詞。
📝 示範場景:粵語閒聊
- 舊模型(普通話錯誤字): "你依家系度做勿?我好中意食那个。"
- 新模型(正確粵語字): "你依家系度做乜?我好钟意食嗰个。"
如何使用新模型
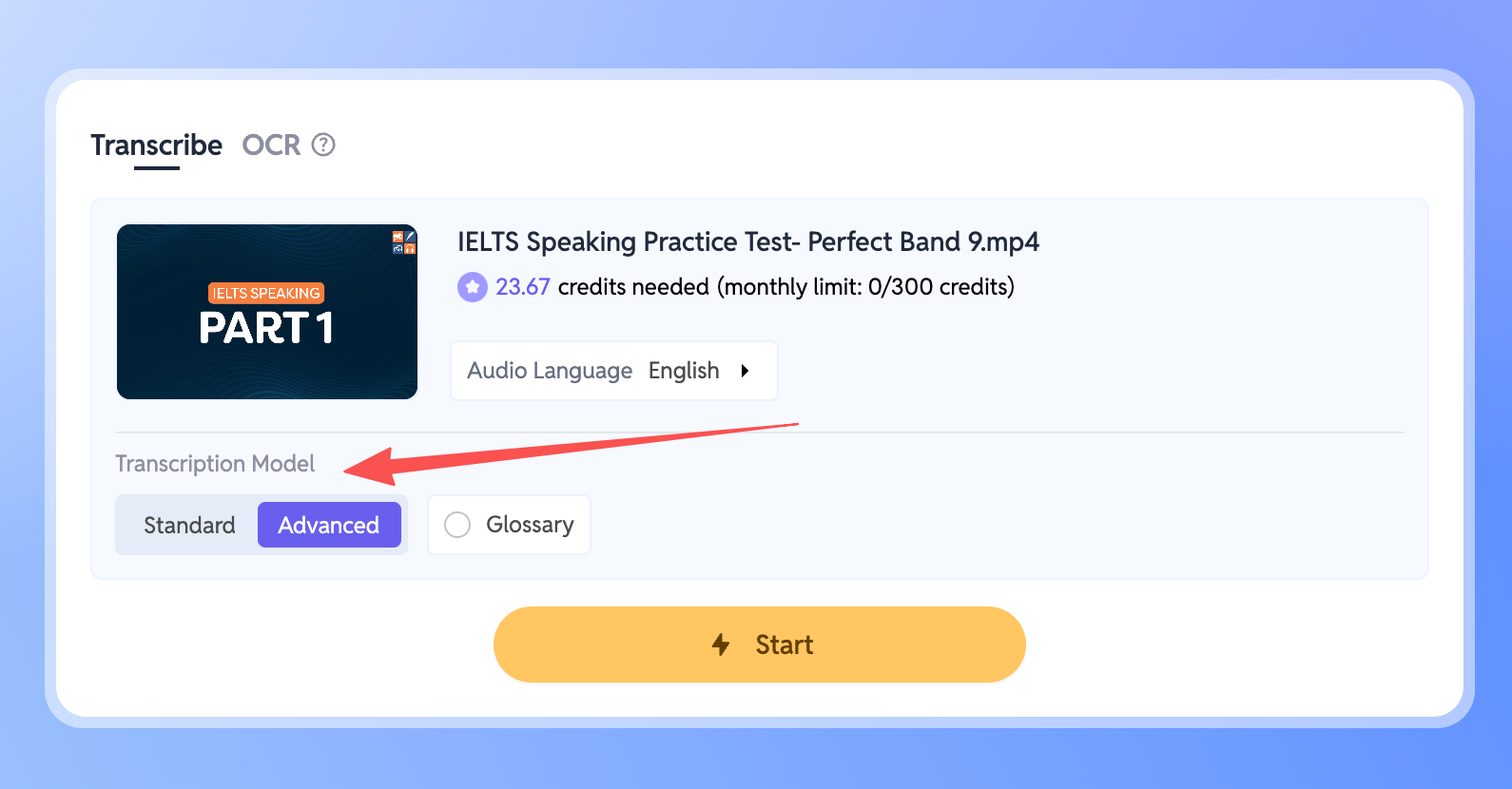
- 進入你的 Workspace,選擇要轉錄的檔案。
- 在側邊欄找到 Transcription Model 設定。
- 只需將模式切換到 Advanced(進階)。
選擇後,新模型會自動處理檔案中的噪音、口音或語言混合情境。
結語
準確率就是效率。SubEasy 新模型升級,專為解決那難搞的 5% 音訊而生——無論是突如其來的語言切換、複雜口音還是嘈雜背景。
我們希望你能花更少時間修字幕,更多時間創作好內容。新模型現已開放試用!